本帖最后由 cc1989summer 于 2024-8-22 23:08 编辑
《人工智能实践教程——从Python入门到机器学习》的第二部分机器学习(第4章、第5章、第6章),主要介绍机器学习的基本概念,以及常见的机器学习的算法,这部分逐渐进入到 本书的核心内容。

第四章主要对机器学习进行总体概述,比如机器学习的分类。常见的机器学习算法:
看了这么多算法介绍,是不是犹如看天书一般,不知所云?
那我们赶快来到第5章,也就是4个经典算法的介绍:
1. 主成分分析(PCA)
2. K均值(K-Means)
3. K近邻(KNN)
4. 梯度下降法
针对主成分分析(PCA),书本是这么介绍的:
主成分分析(PCA) 是一种统计过程,它使用正交变换将一组可能相关变量的观测值转换为称为主成分的线性不相关变量的值。该技术因其能够降低数据维数同时保留数据集中的大部分变化而得到广泛认可。 PCA的本质在于它能够从数据表中提取本质信息,压缩数据集的大小,简化数据集的描述,同时保留所有变量中最有价值的部分。
PCA 的核心原则涉及识别方向或轴,沿着这些方向或轴,数据的可变性最大化。第一个主成分是使数据方差最大化的方向。第二主成分与第一主成分正交。它确定了后续最高方差的方向,依此类推。此过程允许 PCA 将复杂的数据集减少到较低的维度,从而更容易分析和可视化数据,而不会造成大量信息丢失。
PCA 在简化复杂数据集同时保留基本信息方面的美妙之处是无与伦比的。它使数据科学家和统计学家能够发现数据中隐藏的模式,从而促进更明智的决策。通过关注最重要的组成部分,PCA 有助于突出数据的底层结构,从而更清晰地洞察所分析数据的真实性质。该方法提高了数据分析的效率。它有助于更真实、更深刻地理解数据的内在属性。
看完是不是还是不之所云?这就是本书的特点之一:理论性强于实践性,各部分理论都有涉及,对应的Python算法实例也有,但是对于人工智能、机器学习领域的小白来说,单靠本书的内容是很难以理解并入门的,也就是常说的:字都懂,但连在一起就不懂了。
为了理解主成分分析法,你可能要大量的搜索,阅读实例,一步步加深认识。
下面是我搜集的一些概念及实例,有助于加深读者的理解:
主成分分析(PCA)是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。例如,使用PCA可将30个相关(很可能冗余)的环境变量转化为5个无关的成分变量,并且尽可能地保留原始数据集的信息。
在基因组学领域,PCA 简化了遗传数据,通常涉及数千个变量。通过降维,PCA 使研究人员能够更有效地识别与疾病相关的遗传标记和模式,从而促进个性化医学和进化研究的突破。
在图像压缩领域,PCA减少了像素数据中的冗余,实现了图像的高效存储和传输,而不会造成质量的显着损失。该应用在卫星图像和远程医疗等带宽有限的领域至关重要,并且必须在压缩与保留图像完整性之间取得平衡。
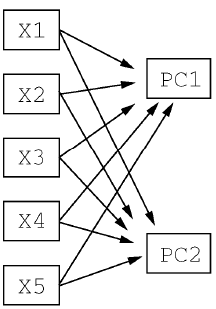
主成分分析模型,变量(X1到X5)映射为主成分(PC1,PC2),也就是实现了降维。
说这么多,不如举个例子吧!
例子1:评选三好学生,每个学生都有很多特征,比如学习成绩、社会实践、思想道德、体育成绩等。在评比中,有一些特征属于“ 无用特征 ”,比如身高、体重、头发长短等,这些特征在评比中是不会考虑的;而有一些特征属于“ 冗余特征 ”,比如各科成绩、总成绩、GPA,实际上这些有一个即可。
例子2:见下图。原本黑色坐标系中需要记录每个点的横纵坐标(xi, yi),也就是 2 个纬度的数据。
但如果转换坐标系,如绿色坐标系所示,让每个点都位于同一条轴上,这样每个点坐标为(xi’, 0),此时仅用x’坐标表示即可,即 1 个维度。
在这个过程中,原先需要保存的 2 维数据变成了 1 维数据,叫做数据降维 / 数据提炼。而PCA的任务形象理解也就是坐标系的转换。
例子3:首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计:
首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼就能看出来,数学,物理,化学这三门课的成绩构成了这组数据的主成分(很显然,数学作为第一主成分,因为数据成绩拉的最开)。
那么为什么我们能一眼看出来呢?当然是我们的坐标轴选对了!!
下面,我们继续看一个表格,下标是一组学生的数学,物理,化学,语文,历史,英语成绩统计:
那么这个表我们能一眼看出来吗?数据太多了,以至于看起来有些凌乱,无法直接看出这组数据的主成分,因为在坐标系下这组数据分布的很散乱。究其原因,是因为无法拨开遮住肉眼的迷雾,如果把这些数据在相应的空间中表示出来,也许你就能换一个观察角度找出主成分.
PCA其实目的就是寻找这个转换后的坐标系,使数据能尽可能分布在一个或几个坐标轴上,同时尽可能保留原先数据分布的主要信息,使原先高维度的信息,在转换后能用低维度的信息来保存。而新坐标系的坐标轴,称为主成分(Principal components, PC),这也就是PCA的名称来源。
PCA分析的一般步骤如下:
- 数据预处理。PCA根据变量间的相关性来推导结果。用户可以输入原始数据矩阵或者相关系数矩阵到
- 判断要选择的主成分数目(这里不涉及因子分析)。
- 选择主成分(这里不涉及旋转)。
- 解释结果。
- 计算主成分得分。
我们跑一段书本上的例程看下:
源数据data.csv,也就是我们降维前的:
源代码:
PCA-简单例子.py
- import numpy as np
- import matplotlib.pyplot as plt
-
- data = np.genfromtxt("data.csv", delimiter=",")
- x_data = data[:,0]
- y_data = data[:,1]
- plt.scatter(x_data,y_data)
- plt.show()
- print(x_data.shape)
-
- def zeroMean(dataMat):
-
- meanVal = np.mean(dataMat, axis=0)
- newData = dataMat - meanVal
- return newData, meanVal
- newData,meanVal=zeroMean(data)
-
- covMat = np.cov(newData, rowvar=0)
-
- print(covMat)
-
- eigVals, eigVects = np.linalg.eig(np.mat(covMat))
-
- print(eigVals)
-
- print(eigVects)
-
- eigValIndice = np.argsort(eigVals)
- print(eigValIndice)
- top = 1
-
- n_eigValIndice = eigValIndice[-1:-(top+1):-1]
- print(n_eigValIndice)
-
- n_eigVect = eigVects[:,n_eigValIndice]
- print(n_eigVect)
-
- lowDDataMat = newData*n_eigVect
- print(lowDDataMat)
-
- reconMat = (lowDDataMat*n_eigVect.T) + meanVal
- print(reconMat)
-
- data = np.genfromtxt("data.csv", delimiter=",")
- x_data = data[:,0]
- y_data = data[:,1]
- plt.scatter(x_data,y_data)
-
- x_data = np.array(reconMat)[:,0]
- y_data = np.array(reconMat)[:,1]
- plt.scatter(x_data,y_data,c='r')
- plt.show()
-
-
-
直接运行代码会提示错误:ModuleNotFoundError: No module named 'numpy'
也就是没有安装numpy组件
什么是 NumPy?
NumPy 是 Python 中科学计算的基本包。它是一个 Python 库,它提供了多维数组对象、各种派生对象(如掩蔽数组和矩阵)以及用于数组快速操作的各种例程,包括数学、逻辑、形状操作、排序、选择、I/O、离散 Fourier 变换、基本线性代数、基本统计操作、随机模拟等。
NumPy 包的核心是 ndarray 对象。这将封装同质数据类型的 n 维数组,在编译的代码中执行许多操作以进行性能操作。NumPy 阵列和标准 Python 序列之间存在几个重要区别:
NumPy 数组在创建时具有固定大小,与 Python 列表不同(可以动态增长)。更改 ndarray 的大小将创建一个新数组并删除原始数组。
NumPy 数组中的元素都需要具有相同的数据类型,因此内存大小相同。例外情况:可以具有 (Python,包括 NumPy) 对象的数组,从而允许不同大小的元素数组。
NumPy 阵列便于对大量数据进行高级数学运算和其他类型的操作。通常,与使用 Python 的内置序列时,此类操作的执行效率更高,代码更少。
越来越多的科学和数学 Python 包正在使用 NumPy 数组;虽然这些通常支持 Python 序列输入,但它们在处理之前将此类输入转换为 NumPy 数组,并且它们经常输出 NumPy 数组。换句话说,为了有效地使用当今许多(甚至可能大多数)基于科学 / 数学 Python 的软件,仅仅知道如何使用 Python 的内置序列类型是不够的 —— 人们还需要知道如何使用 NumPy 数组。
按网上搜索到的教程安装NumPy组件
选择与自己python版本对应的。例如我的是Python3.12,Windows64位,所以下载如下的。
确认安装成功:
然后又提示错误:ModuleNotFoundError: No module named 'matplotlib'
原来还要安装matplotlib模块
Matplotlib 是Python的一个综合性的库,可创建静态的、动画的和可交互的可视化图形图像。
按网上的方法安装matplotlib模块
终于安装完成,用pip list查询已安装模块:
终于运行成功,完成坐标系转换。
本次的学习分享就到这里。


 提升卡
提升卡 变色卡
变色卡 千斤顶
千斤顶

 1/10
1/10 





 京公网安备 11010802033920号
Copyright © 2005-2025 EEWORLD.com.cn, Inc. All rights reserved
京公网安备 11010802033920号
Copyright © 2005-2025 EEWORLD.com.cn, Inc. All rights reserved
